
These two are my favorite balance of fundamentals and getting to purposeful application as quickly as possible (the first link is definitely not enough, but combined with the second she should be comfortable with the syntax and able to get basic things working):
https://www.kaggle.com/learn/intro-to-programming
https://www.kaggle.com/learn/python
This one takes its time with fundamentals and includes some projects to put them in context of building something. It's presented on Google Colab and Jupyter notebooks: https://allendowney.github.io/ThinkPython/
Working with GIS data means cleaning data. This one covers that and a lot of common analysis tools and techniques. But it assumes a bit of programming knowledge (Good to follow up after one of the options above): https://wesmckinney.com/book/
FYI - The URL in the post is:
https://github.com/Dark-Alex-17/managarrl
But the correct URL is:
https://github.com/Dark-Alex-17/managarr
Paste from clipboard is different than paste from primary selection
I have no idea why improperly is in quotes. Maybe it's this reporter's and editor's version of saying that it's allegedly improper?
For months, the agency “improperly” hosted a publicly available spreadsheet on its website that included a hidden tab with partial passwords for its voting machines.
In its statement, the Department of State said that there are two unique passwords for each of its voting machines, which are stored in separate places. Additionally, the passwords can only be used by a person who is physically operating the system and voting machines are stored in secure areas that require ID badges to access and are under 24/7 video surveillance.
Colorado voters use paper ballots, ensuring that a physical paper trail that can be used to verify results tabulated electronically.
Does KDE not have the middle mouse button paste from the primary selection? I thought the clipboard is distinct from primary selection.
the [@] kde [@] [domain name] parts at the bottom of the post body tells a Mastodon server to notify the Lemmy services about the post and Lemmy shows that post as part of the community so subscribers and people browsing all will have the post in their front page feed depending on their sort settings.
Good news from September:
Introducing the Ghostty "Quick Terminal" feature: a terminal that drops-down based on a global keybind (also sometimes known as a Doom or Quake-style terminal). This was one of Ghostty's most requested features.
I think that Hashimoto is using this project to iron out details that are left unaddressed due to convenience for other projects and the very low impact of any single issue Hashimoto has addressed. But much like with Apple projects, Hashimoto intends for the the end product to have greater value than the sum of the parts. Unlike Apple, it will be perfomant cross platform.
I think the only way to evaluate a project like this is to ignore the feature comparison charts and use it to see if it really is better when those details are addressed. I have a feeling that many people will agree and most will shrug their shoulders and not give it a second look if they even gave it a first one.
I'll be trying Ghostty out soon. I hope it's great. But I'm not expecting to be blown away.
He seems to target GTK based on his statement:
"On macOS, the main GUI experience is written in Swift using AppKit and SwiftUI. The tabs are native tabs, the splits are native UI components, multi-window works as you'd expect, etc. On Linux, the GUI experience is GTK using real GTK windows and other widgets.
Features such as error messages are not implemented with a specialized terminal view, we actually use real native UI components. The point is, while the terminal surface and core logic is cross-platform, the user interaction is all purpose-built for each operating system for a true native experience."
https://mitchellh.com/writing/ghostty-and-useful-zig-patterns
Lemmy still doesn't let someone post an embedded link and picture. People don't realize that you have to include the linkin the body of the post which is annoying and intuitive, specially because when creating a new post Lemmy will allow you to fill out both form fields for link and picture but only use one.
I'm not sure I understand the trade offs you're choosing by deploying this way. The benefit of simplicity an speed of deployment seems clear from your write-up. But are those the most important considerations? Why or why not?
Hence why I provided information for people using Android phones.
Working for me now. 2 hours after your post.
Orphaning bcachefs-tools in Debian – Jonathan Carter | 29 August 2024
29 August 2024
Jonathan Carter writes:
> As it stands now, bcachefs-tools is impossible to maintain in Debian stable. While my primary concerns when packaging, are for Debian unstable and the next stable release, I also keep in mind people who have to support these packages long after I stopped caring about them (like Freexian who does LTS support for Debian or Canonical who has long-term Ubuntu support, and probably other organisations that I’ve never even heard of yet). And of course, if bcachfs-tools don’t have any usable stable releases, it doesn’t have any LTS releases either, so anyone who needs to support bcachefs-tools long-term has to carry the support burden on their own, and if they bundle it’s dependencies, then those as well. > > I don’t have any solution for fixing this. I suppose if I were upstream I might look into the possibility of at least supporting a larger range of recent dependencies (usually easy enough if you don’t hop onto the newest features right away) so that distributions with stable releases only need to concern themselves with providing some minimum recent versions, but even if that could work, the upstream author is 100% against any solution other than vendoring all its dependencies with the utility and insisting that it must only be built using these bundled dependencies. I’ve made 6 uploads for this package so far this year, but still I constantly get complaints that it’s out of date and that it’s ancient. If a piece of software is considered so old that it’s useless by the time it’s been published for two or three months, then there’s no way it can survive even a usual stable release cycle, nevermind any kind of long-term support. > > With this in mind ... I decided to remove bcachefs-tools from Debian completely. Although after discussing this with another DD, I was convinced to orphan it instead, which I have now done. I made an upload to experimental so that it’s still available if someone wants to work on it (without having to go through NEW again), it’s been removed from unstable so that it doesn’t migrate to testing, and the ancient (especially by bcachefs-tools standards) versions that are in stable and oldstable will be removed too, since they are very likely to cause damage with any recent kernel versions that support bcachefs.
It seems that this is one more iteration of the conflict between Debian's focus on stability vs the desire to use the latest products, tool, and features.
I'm happy to see that instead of removing bcachefs-tools completely, that the package has been orphaned so it will be easier for someone to pick up maintenance of the package. I'm excited to see bcachefs get closer to becoming a mainstream filesystem, but it will take time to get there as issues like these will have to be worked through for any LTS/stability focused distribution.
Learn PyTorch for Deep Learning: Zero to Mastery | Free Online Book | Daniel Bourke
Learn important machine learning concepts hands-on by writing PyTorch code.

> ### About this course > Who is this course for? > > You: Are a beginner in the field of machine learning or deep learning or AI and would like to learn PyTorch. > > This course: Teaches you PyTorch and many machine learning, deep learning and AI concepts in a hands-on, code-first way. > > If you already have 1-year+ experience in machine learning, this course may help but it is specifically designed to be beginner-friendly. > > What are the prerequisites? > - 3-6 months coding Python. > - At least one beginner machine learning course (however this might be able to be skipped, resources are linked for many different topics). > - Experience using Jupyter Notebooks or Google Colab (though you can pick this up as we go along). > - A willingness to learn (most important).
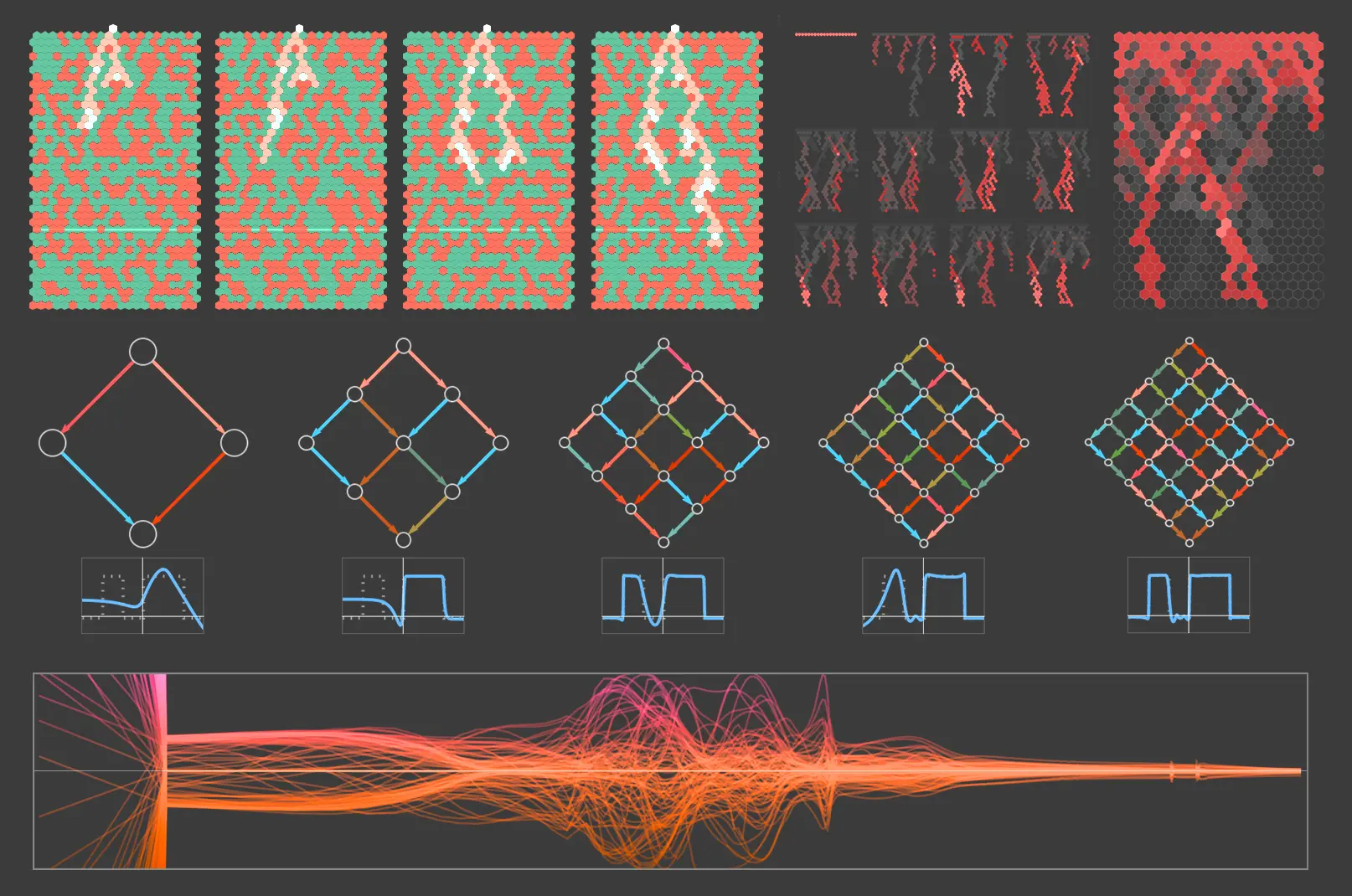
What’s Really Going On in Machine Learning? Some Minimal Models | Stephen Wolfram | August 22, 2024
Stephen Wolfram explores minimal models and their visualizations, aiming to explain the underneath functionality of neural nets and ultimately machine learning.
Deno's Standard Library for JavaScript Finally Stabilized at v1 | 3min 5sec Video | Aug 8, 2024
Video Description
> Many programming languages have standard libraries. What about JavaScript? 🤔️ > > Deno's goal is to simplify programming, and part of that is to provide the JavaScript community with a carefully audited standard library (that works in Deno and Node) that offers utility functions for data manipulation, web-related logic, and more. We created the Deno Standard Library in 2021, and four years, 151 releases, and over 4k commits later, we're thrilled to finally announce that it's 30 modules are finally stabilized at v1. > > Learn more about the Deno Standard Library > > Read about our stabilization process for the library
Data Science Handbook | Curated resources (Free & Paid) to help data scientists learn, grow, and break into the field of data science | Andres Vourakis | Last update Jul 23, 2024
This is a repo with links to everything you'd ever want to learn about data science - GitHub - andresvourakis/data-scientist-handbook: This is a repo with links to everything you'd ever wa...
Andres Vourakis writes:
> ### Data Scientist Handbook 2024 > > Curated resources (Free & Paid) to help data scientists learn, grow, and break into the field of data science.
> Even though there are hundreds of resources out there (too many to keep track of), I will try to limit them to a maximum of 5 per category to ensure you get the most valuable and relevant resources out there, plus, the whole point of this repository is to help you avoid getting overwhelmed by too many choices. This way you can focus less time researching and more time learning.
> ### FAQs > > - How is curation done? Curation is based on thorough research, recommendations from people I trust, and my years of experience as a Data Scientist. > - Are all resources free? Most resources here will be free, but I will also include paid alternatives if they are truly valuable to your career development. All paid resources include the symbol 💲. > - How often is the repository updated? I plan to come back here as often as possible to ensure all resources are still available and relevant and also to add new ones.
How OCaml type checker works -- or what polymorphism and garbage collection have in common | okmij.org | original February 2013 | updated January 9, 2022
> There is more to Hindley-Milner type inference than the Algorithm W. In 1988, Didier Rémy was looking to speed up the type inference in Caml and discovered an elegant method of type generalization. Not only it is fast, avoiding scanning the type environment. It smoothly extends to catching of locally-declared types about to escape, to type-checking of universals and existentials, and even to MLF. > > Alas, both the algorithm and its implementation in the OCaml type checker are little known and little documented. This page is to explain and popularize Rémy's algorithm, and to decipher a part of the OCaml type checker. The page also aims to preserve the history of Rémy's algorithm.
Writing a C Compiler | Build a Real Programming Language from Scratch | Nora Sandler | July 2024 | No Starch Press | 792 pages | ISBN-13: 9781718500426
A fun, hands-on guide to writing your own compiler for a real-world programming language.

Book Description
Writing a C Compiler will take you step by step through the process of building your own compiler for a significant subset of C—no prior experience with compiler construction or assembly code needed. Once you’ve built a working compiler for the simplest C program, you’ll add new features chapter by chapter. The algorithms in the book are all in pseudocode, so you can implement your compiler in whatever language you like. Along the way, you’ll explore key concepts like:
- Lexing and parsing: Learn how to write a lexer and recursive descent parser that transform C code into an abstract syntax tree.
- Program analysis: Discover how to analyze a program to understand its behavior and detect errors.
- Code generation: Learn how to translate C language constructs like arithmetic operations, function calls, and control-flow statements into x64 assembly code.
- Optimization techniques: Improve performance with methods like constant folding, dead store elimination, and register allocation.
Compilers aren’t terrifying beasts—and with help from this hands-on, accessible guide, you might even turn them into your friends for life.
Author Bio
Nora Sandler is a software engineer based in Seattle. She holds a BS in computer science from the University of Chicago, where she researched the implementation of parallel programming languages. More recently, she’s worked on domain-specific languages at an endpoint security company. You can find her blog on pranks, compilers, and other computer science topics at https://norasandler.com.
A table of publicly available Arena crates and their features
Sometimes you just really need an arena. Sometimes for performance reasons, other times for lifetime-related reasons. In their most basic forms, they're just a vec with some extra guarantees. However, it's those extra guarantees that matter. I've found myself looking for the right kind of arena too ...
For a technical discussion of using arenas for memory allocation with an example implementation, see gingerBill's Memory Allocation Strategies - Part 2: Linear/Arena Allocators
Discover how the Rust compiler optimizes dynamically dispatched tail calls and manages memory when using trait objects in this in-depth tutorial. Gain a deeper understanding of how vtables and the Rust memory model work together to improve the performance of your code.
EventHelix writes:
> This article will investigate how Rust handles dynamic dispatch using trait objects and vtables. We will also explore how the Rust compiler can sometimes optimize tail calls in the context of dynamic dispatch. Finally, we will examine how the vtable facilitates freeing memory when using trait objects wrapped in a Box.
First impressions of Gleam: lots of joys and some rough edges
> The blog post is the author's impressions of Gleam after it released version 1.4.0. Gleam is an upcoming language that is getting a lot of highly-ranked articles. > > It runs on the Erlang virtual machine (BEAM), making it great for distributed programs and a competitor to Elixir and Erlang (the language). It also compiles to JavaScript, making it a competitor to TypeScript. > > But unlike Elixir, Erlang, and TypeScript, it's strongly typed (not just gradually typed). It has "functional" concepts like algebraic data types, immutable values, and first-class functions. The syntax is modeled after Rust and its tutorial is modeled after Go's. Lastly, it has a very large community.
Elements of Data Science | Allen B. Downey | July 17, 2024
I’m excited to announce the launch of my newest book, Elements of Data Science. As the subtitle suggests, it is about “Getting started with Data Science and Python”. Order now fro…

July 17, 2024
Allen B. Downey writes:
> Elements of Data Science is an introduction to data science for people with no programming experience. My goal is to present a small, powerful subset of Python that allows you to do real work with data as quickly as possible. > > Part 1 includes six chapters that introduce basic Python with a focus on working with data. > > Part 2 presents exploratory data analysis using Pandas and empiricaldist — it includes a revised and updated version of the material from my popular DataCamp course, “Exploratory Data Analysis in Python.” > > Part 3 takes a computational approach to statistical inference, introducing resampling method, bootstrapping, and randomization tests. > > Part 4 is the first of two case studies. It uses data from the General Social Survey to explore changes in political beliefs and attitudes in the U.S. in the last 50 years. The data points on the cover are from one of the graphs in this section. > > Part 5 is the second case study, which introduces classification algorithms and the metrics used to evaluate them — and discusses the challenges of algorithmic decision-making in the context of criminal justice. > > This project started in 2019, when I collaborated with a group at Harvard to create a data science class for people with no programming experience. We discussed some of the design decisions that went into the course and the book in this article.
Read Elements of Data Science in the form of Jupyter notebooks.
Why you should fall in love with the RP2350 | Dmitry Grinberg | Aug 8, 2024
Dmitry.GR: Everything you ever dreamed the RP2040 would be is here - fall in love with the RP2350

> Dmitry Grinberg writes: > > > go replan all your STM32H7 projects with RP2350, save money, headaches, and time. As a bonus, you’ll get an extra core to play with too! "But," you might say, "STMicro chips come with internal flash, while RP2350 still requires an external SPI chip to store the flash". Hold on to your hats... there are now RP2350 variants with built-in flash! They are called RP2354A nd RP2354B and they include 2MBytes of flash in-package. The pinouts are the same as the RP2350A/B, for a bonus! Why two pinouts? Because the "more GPIOs" dream also came true! There is now a variant with more GPIOS, available in an 80-pin package. That’s right! It is epic! > > Read Why you should fall in love with the RP2350
Why you should fall in love with the RP2350 | Dmitry Grinberg | Aug 8, 2024
Dmitry.GR: Everything you ever dreamed the RP2040 would be is here - fall in love with the RP2350

Dmitry Grinberg writes:
> go replan all your STM32H7 projects with RP2350, save money, headaches, and time. As a bonus, you’ll get an extra core to play with too! "But," you might say, "STMicro chips come with internal flash, while RP2350 still requires an external SPI chip to store the flash". Hold on to your hats... there are now RP2350 variants with built-in flash! They are called RP2354A nd RP2354B and they include 2MBytes of flash in-package. The pinouts are the same as the RP2350A/B, for a bonus! Why two pinouts? Because the "more GPIOs" dream also came true! There is now a variant with more GPIOS, available in an 80-pin package. That’s right! It is epic!
COSMIC ALPHA 1 Released (Desktop Environment Written In Rust From System76)
System76 computers empower the world's curious and capable makers of tomorrow
As the first alpha version of COSMIC Epoch 1, it is incomplete. You’ll most certainly find bugs. Testing and bug reports are welcome and appreciated. New feature requests will be considered for Epoch 2, COSMIC’s second release.
COSMIC Epoch 1 (alpha 1) on the Pop!_OS 24.04 LTS alpha ISO files are available
Try COSMIC on other Linux distributions
Fedora - See instructions
NixOS - See instructions
Arch - See instructions
openSUSE - Coming soon
Serpent OS - See instructions
Redox OS - includes some COSMIC Components - See Progress
https://system76.com/cosmic
Dremio is offering free pdf copies of "Apache Iceberg: The Definitive Guide: Data Lakehouse Functionality, Performance and Scalability on the Data Lake"
The Dremio Unified Lakehouse Platform for self-service analytics and AI, powered by a performant SQL Query Engine and Apache-native Lakehouse Management
Book Preface:
> Welcome to Apache Iceberg: The Definitive Guide! We’re delighted you have embarked on this learning journey with us. In this preface, we provide an overview of this book, why we wrote it, and how you can make the most of it. > > ### About This Book > > In these pages, you’ll learn what Apache Iceberg is, why it exists, how it works, and how to harness its power. Designed for data engineers, architects, scientists, and analysts working with large datasets across various use cases from BI dashboards to AI/ML, this book explores the core concepts, inner workings, and practical applications of Apache Iceberg. By the time you reach the end, you will have grasped the essentials and possess the practical knowledge to implement Apache Iceberg effectively in your data projects. Whether you are a newcomer or an experienced practitioner, Apache Iceberg: The Definitive Guide will be your trusted companion on this enlightening journey into Apache Iceberg. > > ### Why We Wrote This Book > > As we observed the rapid growth and adoption of the Apache Iceberg ecosystem, it became evident that a growing knowledge gap needed to be addressed. Initially, we began by sharing insights through a series of blog posts on the Dremio platform to provide valuable information to the burgeoning Iceberg community. However, it soon became clear that a comprehensive and centralized resource was essential to meet the increasing demand for a definitive Iceberg reference. This realization was the driving force behind the creation of Apache Iceberg: The Definitive Guide. Our goal is to provide readers with a single authoritative source that bridges the knowledge gap and empowers individuals and organizations to make the most of Apache Iceberg’s capabilities in their data-related endeavors. > > ### What You Will Find Inside > > In the following chapters, you will learn what Apache Iceberg is and how it works, how you can take advantage of the format with a variety of tools, and best practices to manage the quality and governance of the data in Apache Iceberg tables. Here is a summary of each chapter’s content: > > - Chapter 1, “Introduction to Apache Iceberg” > Exploration of the historical context of data lakehouses and the essential concepts underlying Apache Iceberg. > - Chapter 2, “The Architecture of Apache Iceberg” > Deep dive into the intricate design of Apache Iceberg, examining how its various components function together. > - Chapter 3, “Lifecycle of Write and Read Queries” > Examination of the step-by-step process involved in Apache Iceberg transactions, highlighting updates, reads, and time-travel queries. > - Chapter 4, “Optimizing the Performance of Iceberg Tables” > Discussions on maintaining optimized performance in Apache Iceberg tables through techniques such as compaction and sorting. > - Chapter 5, “Iceberg Catalogs” > In-depth explanation of the role of Apache Iceberg catalogs, exploring the different catalog options available. > - Chapter 6, “Apache Spark” > Practical sessions using Apache Spark to manage and interact with Apache Iceberg tables. > - Chapter 7, “Dremio’s SQL Query Engine” > Exploration of the Dremio lakehouse platform, focusing on DDL, DML, and table optimization for Apache Iceberg tables. > - Chapter 8, “AWS Glue” > Demonstration of the use of AWS Glue Catalog and AWS Glue Studio for working with Apache Iceberg tables. > - Chapter 9, “Apache Flink” > Practical exercises in using Apache Flink for streaming data processing with Apache Iceberg tables. > - Chapter 10, “Apache Iceberg in Production” > Insights into managing data quality in production, using metadata tables for table health monitoring and employing table and catalog versioning for various operational needs. > - Chapter 11, “Streaming with Apache Iceberg” > Use of tools such as Apache Spark, Flink, and AWS Glue for streaming data processing into Iceberg tables. > - Chapter 12, “Governance and Security” > Exploration of the application of governance and security at various levels in Apache Iceberg tables, such as storage, semantic layers, and catalogs. > - Chapter 13, “Migrating to Apache Iceberg” > Guidelines on transforming existing datasets from different file types and databases into Apache Iceberg tables. > - Chapter 14, “Real-World Use Cases of Apache Iceberg” > A look at real-world applications of Apache Iceberg, including business intelligence dashboards and implementing change data capture > > Direct link to PDF > > Dremio bills itself as a "Unified Analytics Platform for a Self-Service Lakehouse". The authors of the book work for Dremio and may have ownership interest in Dremio.
Using and setting up Neovim in Windows 11 (not WSL)
What issues or frustrations have you encountered in trying to use and set up Neovim in Windows 11?
I'm currently writing up my experience with installing, setting up, and using Neovim in Windows and would like to hear from others that have tried the same. What was annoying, difficult, or impossible in your experience?
System76 with Jeremy Soller | Rust in Production Podcast S02 E07 by corrode Rust Consulting | 2024-07-25
Many devs dream of one day writing their own operating system. Ideally in their favorite language: Rust. For many of us, this dream remains just that: a dream. Jeremy Soller from System76, however, didn't just contribute kernel code for Pop!_OS, but also started his own operating system, RedoxOS, wh...

> Many devs dream of one day writing their own operating system. Ideally in their favorite language: Rust. For many of us, this dream remains just that: a dream. > > Jeremy Soller from System76, however, didn't just contribute kernel code for Pop!_OS, but also started his own operating system, RedoxOS, which is completely written in Rust. One might get the impression that he likes to tinker with low-level code! > > In this episode of Rust in Production, Jeremy talks about his journey. From getting hired as a kernel developer at Denver-based company System76 after looking at the job ad for 1 month and finally applying, to being the maintainer of not one but two operating systems, additional system tools, and the Rust-based Cosmic desktop. We'll talk about why it's hard to write correct C code even for exceptional developers like Jeremy and why Rust is so great for refactoring and sharing code across different levels of abstraction.
Listen to Rust in Production Podcast S02 E07
System76 with Jeremy Soller | Rust in Production Podcast S02 E07 by corrode Rust Consulting | 2024-07-25
Many devs dream of one day writing their own operating system. Ideally in their favorite language: Rust. For many of us, this dream remains just that: a dream. Jeremy Soller from System76, however, didn't just contribute kernel code for Pop!_OS, but also started his own operating system, RedoxOS, wh...

> Many devs dream of one day writing their own operating system. Ideally in their favorite language: Rust. For many of us, this dream remains just that: a dream. > > Jeremy Soller from System76, however, didn't just contribute kernel code for Pop!_OS, but also started his own operating system, RedoxOS, which is completely written in Rust. One might get the impression that he likes to tinker with low-level code! > > In this episode of Rust in Production, Jeremy talks about his journey. From getting hired as a kernel developer at Denver-based company System76 after looking at the job ad for 1 month and finally applying, to being the maintainer of not one but two operating systems, additional system tools, and the Rust-based Cosmic desktop. We'll talk about why it's hard to write correct C code even for exceptional developers like Jeremy and why Rust is so great for refactoring and sharing code across different levels of abstraction.
Listen to Rust in Production Podcast S02 E07
System76 with Jeremy Soller | Rust in Production Podcast S02 E07 by corrode Rust Consulting | 2024-07-25
Many devs dream of one day writing their own operating system. Ideally in their favorite language: Rust. For many of us, this dream remains just that: a dream. Jeremy Soller from System76, however, didn't just contribute kernel code for Pop!_OS, but also started his own operating system, RedoxOS, wh...

> > Many devs dream of one day writing their own operating system. Ideally in their favorite language: Rust. For many of us, this dream remains just that: a dream. > > > > Jeremy Soller from System76, however, didn't just contribute kernel code for Pop!_OS, but also started his own operating system, RedoxOS, which is completely written in Rust. One might get the impression that he likes to tinker with low-level code! > > > > In this episode of Rust in Production, Jeremy talks about his journey. From getting hired as a kernel developer at Denver-based company System76 after looking at the job ad for 1 month and finally applying, to being the maintainer of not one but two operating systems, additional system tools, and the Rust-based Cosmic desktop. We'll talk about why it's hard to write correct C code even for exceptional developers like Jeremy and why Rust is so great for refactoring and sharing code across different levels of abstraction.
Listen to Rust in Production Podcast S02 E07