
-
OpenWebUI OpenStreetMap Tool 1.3.1
openwebui.com OpenStreetMap Tool Tool | Open WebUI CommunityOpenStreetMap Tool Tool | Open WebUI Community - Allows models to automatically query OpenStreetMap for information and nearby points of interest.
I've been working on keeping the OSM tool up to date for OpenWebUI's rapid development pace. And now I've added better-looking citations, with fancy styling. Just a small announcement post!
-
Qwen2.5-Coder-7B
I've been using Qwen 2.5 Coder (bartowski/Qwen2.5.1-Coder-7B-Instruct-GGUF) for some time now, and it has shown significant improvements compared to previous open weights models.
Notably, this is the first model that can be used with Aider. Moreover, Qwen 2.5 Coder has made notable strides in editing files without requiring frequent retries to generate in the proper format.
One area where most models struggle, including this one, is when the prompt exceeds a certain length. In this case, it appears that the model becomes unable to remember the system prompt when the prompt length is above ~2000 tokens.
-
Having trouble to generate correct output? Try prefixes!
I'm just a hobbyist in this topic, but I would like to share my experience with using local LLMs for very specific generative tasks.
Predefined formats
With prefixes, we can essentially add the start of the LLMs response, without it actually generating it. Like, when We want it to Respond with bullet points, we can set the prefix to be
-(A dash and space). If we want JSON, we can use` ` `json\n{as a prefix, to make it think that it started a JSON markdown code block.If you want a specific order in which the JSON is written, you can set the prefix to something like this:
plaintext ` ` `json { "first_key":Translation
Let's say you want to translate a given text. Normally you would prompt a model like this
plaintext Translate this text into German: ` ` `plaintext [The text here] ` ` ` Respond with only the translation!Or maybe you would instruct it to respond using JSON, which may work a bit better. But what if it gets the JSON key wrong? What if it adds a little ramble infront or after the translation? That's where prefixes come in!You can leave the promopt exactly as is, maybe instructing it to respond in JSON
plaintext Respond in this JSON format: {"translation":"Your translation here"}Now, you can pretend that the LLM already responded with part of the message, which I will call a prefix. The prefix for this specific usecase could be this:plaintext { "translation":"Now the model thinks that it already wrote these tokens, and it will continue the message from right where it thinks it left off. The LLM might generate something like this:plaintext Es ist ein wunderbarer Tag!" }To get the complete message, simply combine the prefix and the generated text to result in this:plaintext { "translation":"Es ist ein wunderschöner Tag!" }To minimize inference costs, you can add"}and"\n}as stop tokens, to stop the generation right after it finished the json entrie.Code completion and generation
What if you have an LLM which didn't train on code completion tokens? We can get a similar effect to the trained tokens using an instruction and a prefix!
The prompt might be something like this
plaintext ` ` `python [the code here] ` ` ` Look at the given code and continue it in a sensible and reasonable way. For example, if I started writing an if statement, determine if an else statement makes sense, and add that.And the prefix would then be the start of a code block and the given code like thisplaintext ` ` `python [the code here]This way, the LLM thinks it already rewrote everything you did, but it will now try to complete what it has written. We can then add\n` ` `as a stop token to make it only generate code and nothing else.This approach for code generation may be more desireable, as we can tune its completion using the prompt, like telling it to use certain code conventions.
Simply giving the model a prefix of
` ` `python\nMakes it start generating code immediately, without any preamble. Again, adding the stop keyword\n` ` `makes sure that no postamble is generated.Using this in ollama
Using this "technique" in ollama is very simple, but you must use the
/api/chatendpoint and cannot use/api/generate. Simply append the start of a message to the conversation passed to the model like this:json "conversation":[ {"role":"user", "content":"Why is the sky blue?"}, {"role":"assistant", "content":"The sky is blue because of"} ]It's that simple! Now the model will complete the message with the prefix you gave it as "content".Be aware!
There is one pitfall I have noticed with this. You have to be aware of what the prefix gets tokenized to. Because we are manually setting the start of the message ourselves, it might not be optimally tokenized. That means, that this might confuse the LLM and generate one too many or few spaces. This is mostly not an issue though, as
What do you think? Have you used prefixes in your generations before?
-
Meta unveils open-source Llama Stack, standardizing AI building blocks across the entire development lifecycle.
github.com GitHub - meta-llama/llama-stack: Model components of the Llama Stack APIsModel components of the Llama Stack APIs. Contribute to meta-llama/llama-stack development by creating an account on GitHub.

Looks interesting. Love seeing more coming out from this space
- qwenlm.github.io Qwen2.5: A Party of Foundation Models!
GITHUB HUGGING FACE MODELSCOPE DEMO DISCORD Introduction In the past three months since Qwen2’s release, numerous developers have built new models on the Qwen2 language models, providing us with valuable feedback. During this period, we have focused on creating smarter and more knowledgeable languag...
https://huggingface.co/collections/Qwen/qwen25-66e81a666513e518adb90d9e
Qwen 2.5 0.5B, 1.5B, 3B, 7B, 14B, 32B, and 72B just came out, with some variants in some sizes just for math or coding, and base models too.
All Apache licensed, all 128K context, and the 128K seems legit (unlike Mistral).
And it's pretty sick, with a tokenizer that's more efficient than Mistral's or Cohere's and benchmark scores even better than llama 3.1 or mistral in similar sizes, especially with newer metrics like MMLU-Pro and GPQA.
I am running 34B locally, and it seems super smart!
As long as the benchmarks aren't straight up lies/trained, this is massive, and just made a whole bunch of models obsolete.
Get usable quants here:
GGUF: https://huggingface.co/bartowski?search_models=qwen2.5
EXL2: https://huggingface.co/models?sort=modified&search=exl2+qwen2.5
-
Testing the Limits: My GTX 1070 Rig vs Mistral Small 22B
Mistral Small 22B just dropped today and I am blown away by how good it is. I was already impressed with Mistral NeMo 12B's abilities, so I didn't know how much better a 22B could be. It passes really tough obscure trivia that NeMo couldn't, and its reasoning abilities are even more refined.
With Mistral Small I have finally reached the plateu of what my hardware can handle for my personal usecase. I need my AI to be able to at least generate around my base reading speed. The lowest I can tolerate is 1.5~T/s lower than that is unacceptable. I really doubted that a 22B could even run on my measly Nvidia GTX 1070 8G VRRAM card and 16GB DDR4 RAM. Nemo ran at about 5.5t/s on this system, so how would Small do?
Mistral Small Q4_KM runs at 2.5T/s with 28 layers offloaded onto VRAM. As context increases that number goes to 1.7T/s. It is absolutely usable for real time conversation needs. I would like the token speed to be faster sure, and have considered going with the lowest Q4 recommended to help balance the speed a little. However, I am very happy just to have it running and actually usable in real time. Its crazy to me that such a seemingly advanced model fits on my modest hardware.
Im a little sad now though, since this is as far as I think I can go in the AI self hosting frontier without investing in a beefier card. Do I need a bigger smarter model than Mistral Small 22B? No. Hell, NeMo was serving me just fine. But now I want to know just how smart the biggest models get. I caught the AI Acquisition Syndrome!
-
Is Arli AI a legit cloud LLM inference service? Any user experience?
I just found https://www.arliai.com/ who offer LLM inference for quite cheap. Without rate-limits and unlimited token generation. No-logging policy and they have an OpenAI compatible API.
I've been using runpod.io previously but that's a whole different service as they sell compute and the customers have to build their own Docker images and run them in their cloud, by the hour/second.
Should I switch to ArliAI? Does anyone have some experience with them? Or can recommend another nice inference service? I still refuse to pay $1.000 for a GPU and then also pay for electricity when I can use some $5/month cloud service and it'd last me 16 years before I reach the price of buying a decent GPU...
Edit: Saw their $5 tier only includes models up to 12B parameters, so I'm not sure anymore. For larger models I'd need to pay close to what other inference services cost.
Edit2: I discarded the idea. 7B parameter models and one 12B one is a bit small to pay for. I can do that at home thanks to llama.cpp
-
Local Notetaker for meetings
I'm currently using SuperNormal to taking meeting minutes for all of my Teams, Google Meet, and Zoom conference calls. Is there a workflow for doing this locally with Whisper and some other tools? I haven't found one yet.
-
Are there any good open source text-to-music models, preferably with lyrical abilities?
Only recently did I discover the text-to-music AI companies (udio.com, suno.com) and I was surprised about how good the results are. Both are under lawsuit from RIAA.
I am curious if there are any local ones I can experiment with or train myself. I know there is facebook/musicgen-large on HuggingFace. That model is over 1 year old and there might be others by now. Also, based on the card I get the feeling that model is not going to be good at doing specific song lyrics (maybe the lyrics just were absent from the training data?). I am most interested in trying my hand at writing songs and fine-tuning a model on specific types of music to get the sounds I am looking for.
-
Mistral AI just dropped their new model, Mistral Large 2
mistral.ai Large EnoughToday, we are announcing Mistral Large 2, the new generation of our flagship model. Compared to its predecessor, Mistral Large 2 is significantly more capable in code generation, mathematics, and reasoning. It also provides a much stronger multilingual support, and advanced function calling capabili...
Another day, another model.
Just one day after Meta released their new frontier models, Mistral AI surprised us with a new model, Mistral Large 2.
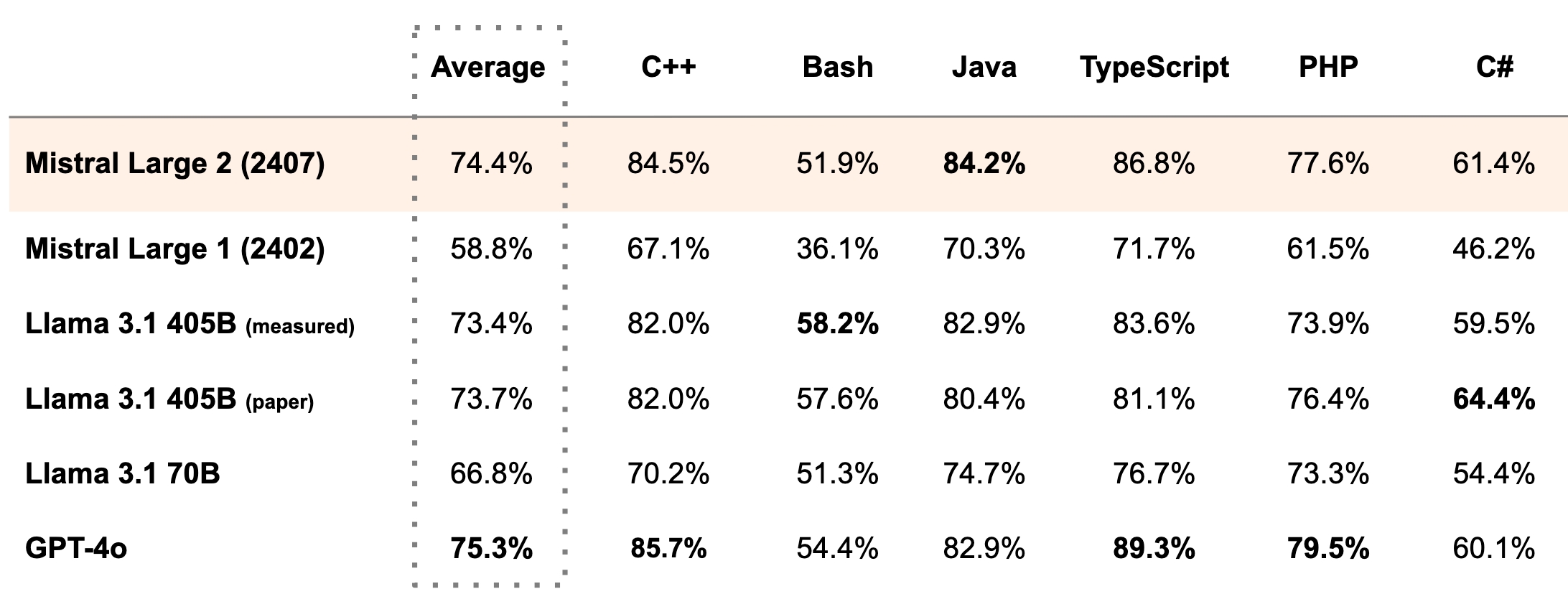
It's quite a big one with 123B parameters, so I'm not sure if I would be able to run it at all. However, based on their numbers, it seems to come close to GPT-4o. They claim to be on par with GPT-4o, Claude 3 Opus, and the fresh Llama 3 405B regarding coding related tasks.
It's multilingual, and from what they said in their blog post, it was trained on a large coding data set as well covering 80+ programming languages. They also claim that it is "trained to acknowledge when it cannot find solutions or does not have sufficient information to provide a confident answer"
On the licensing side, it's free for research and non-commercial applications, but you have to pay them for commercial use.
-
Llama 3.1 is out!
ai.meta.com Introducing Llama 3.1: Our most capable models to dateBringing open intelligence to all, our latest models expand context length, add support across eight languages, and include Meta Llama 3.1 405B— the first frontier-level open source AI model.

Meta has released llama 3.1. It seems to be a significant improvement to an already quite good model. It is now multilingual, has a 128k context window, has some sort of tool chaining support and, overall, performs better on benchmarks than its predecessor.
With this new version, they also released their 405B parameter version, along with the updated 70B and 8B versions.
I've been using the 3.0 version and was already satisfied, so I'm excited to try this.
-
Trying to set up LLama but i get a error saying CUDA has no path set
Hello y'all, i was using this guide to try and set up llama again on my machine, i was sure that i was following the instructions to the letter but when i get to the part where i need to run setup_cuda.py install i get this error
File "C:\Users\Mike\miniconda3\Lib\site-packages\torch\utils\cpp_extension.py", line 2419, in _join_cuda_home raise OSError('CUDA_HOME environment variable is not set. ' OSError: CUDA_HOME environment variable is not set. Please set it to your CUDA install root. (base) PS C:\Users\Mike\text-generation-webui\repositories\GPTQ-for-LLaMa>i'm not a huge coder yet so i tried to use setx to set CUDA_HOME to a few different places but each time doing
echo %CUDA_HOMEdoesn't come up with the address so i assume it failed, and i still can't run setup_cuda.pyAnyone have any idea what i'm doing wrong?
-
A font with an LLM embedded
You type "Once upon a time!!!!!!!!!!" and those exclamation marks are rendered to show the LLM generated text, using a tiny 30MB model
via https://simonwillison.net/2024/Jun/23/llama-ttf/
- ai.meta.com Sharing new research, models, and datasets from Meta FAIR
Meta FAIR is releasing several new research artifacts. Our hope is that the research community can use them to innovate, explore, and discover new ways to apply AI at scale.

- www.wired.com Publishers Target Common Crawl In Fight Over AI Training Data
Long-running nonprofit Common Crawl has been a boon to researchers for years. But now its role in AI training data has triggered backlash from publishers.

-
Why is there no Q8 quantization for Phi-3-V?
Hello! I am looking for some expertise from you. I have a hobby project where Phi-3-vision fits perfectly. However, the PyTorch version is a little too big for my 8GB video card. I tried looking for a quantized model, but all I found is 4-bit. Unfortunately, this model works too poorly for me. So, for the first time, I came across the task of quantizing a model myself. I found some guides for Phi-3V quantization for ONNX. However, the only options are fp32(?), fp16, int4. Then, I found a nice tool for AutoGPTQ but couldn't make it work for the job yet. Does anybody know why there is no int8/int6 quantization for Phi-3-vision? Also, has anybody used AutoGPTQ for quantization of vision models?
-
Alice in Wonderland: Simple Tasks Showing Complete Reasoning Breakdown in SOTA Large Language Models
"Alice has N brothers and she also has M sisters. How many sisters does Alice’s brother have?"
The problem has a light quiz style and is arguably no challenge for most adult humans and probably to some children.
The scientists posed varying versions of this simple problem to various State-Of-the-Art LLMs that claim strong reasoning capabilities. (GPT-3.5/4/4o , Claude 3 Opus, Gemini, Llama 2/3, Mistral and Mixtral, including very recent Dbrx and Command R+)
They observed a strong collapse of reasoning and inability to answer the simple question as formulated above across most of the tested models, despite claimed strong reasoning capabilities. Notable exceptions are Claude 3 Opus and GPT-4 that occasionally manage to provide correct responses.
This breakdown can be considered to be dramatic not only because it happens on such a seemingly simple problem, but also because models tend to express strong overconfidence in reporting their wrong solutions as correct, while often providing confabulations to additionally explain the provided final answer, mimicking reasoning-like tone but containing nonsensical arguments as backup for the equally nonsensical, wrong final answers.
-
Does anyone know where the old original GPT-2 (transformer) model ended up?
Remember 2-3 years ago when OpenAI had a website called transformer that would complete a sentence to write a bunch of text. Most of it was incoherent but I think it is important for historic and humor purposes.
{kind=link}